Core ML & On-Device ML Development
Vision, Core ML, Natural Language, on-device voice. Models that run locally without the latency, privacy cost, or cloud bill of a server round-trip. I've built three of my own apps whose entire value is on-device inference.
- on-device Vision and Core ML pipelines with sub-100ms latency budgets
- PyTorch/TensorFlow → Core ML conversion, quantization, model size reduction
- on-device voice AI with ElevenLabs fallback for real-time conversations
What clients say
"Vadim was instrumental to the success Epsy enjoyed on iOS, taking it from an idea on a Miro board to the highest rated and most downloaded app of its kind on the store."
James C. · Mobile Engineering Lead, Epsy
"We had a strict deadline, and Vadim managed to complete the job in time. He gave us meaningful feedback and suggested better approaches, not trying to blindly stick to our specification."
Founder · Pre-seed streaming service
"I can say with confidence that it will be difficult to find a better developer. Vadim is achievement-oriented, highly organized, with very good communication skills."
Alex Z. · Co-Founder, eda.so
Related work

Why your Core ML model ships wrong
A Core ML developer on why on-device ML drifts between the lab and the field, and why the fix is rarely the model itself.
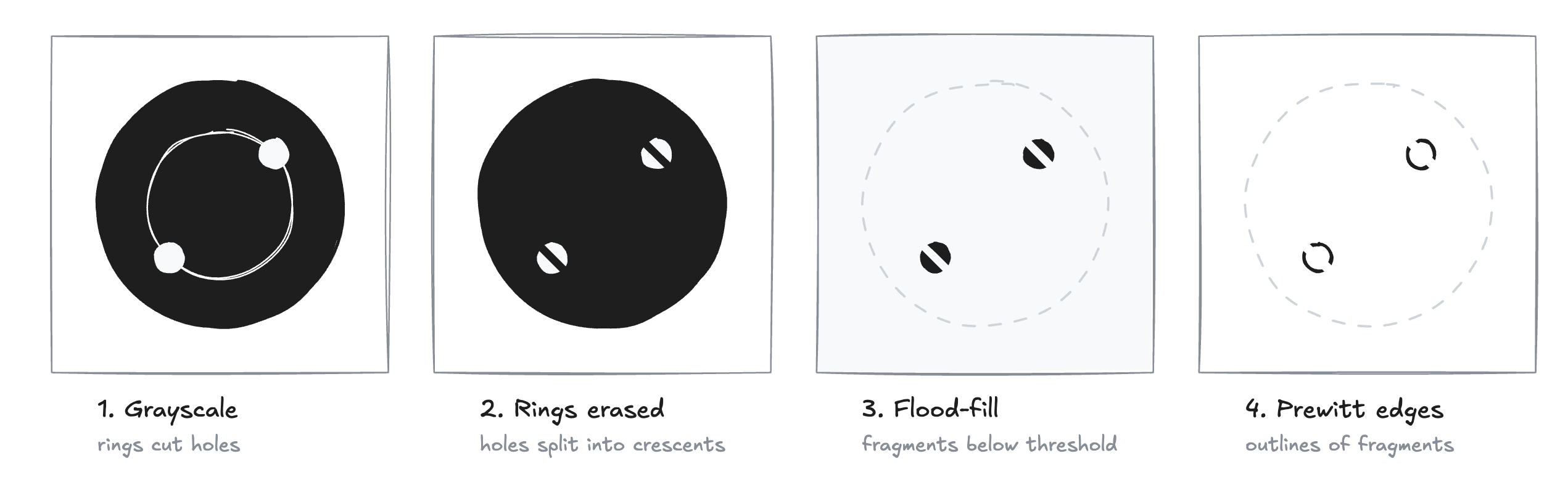
My Phone Replaced a Brass Plug
I wanted to cook venison from scratch, which meant learning to shoot, which meant keeping track of my progress, which meant porting a 2012 OpenCV paper and training a state-of-the-art computer vision model, which meant the dinner took a bit longer than expected.
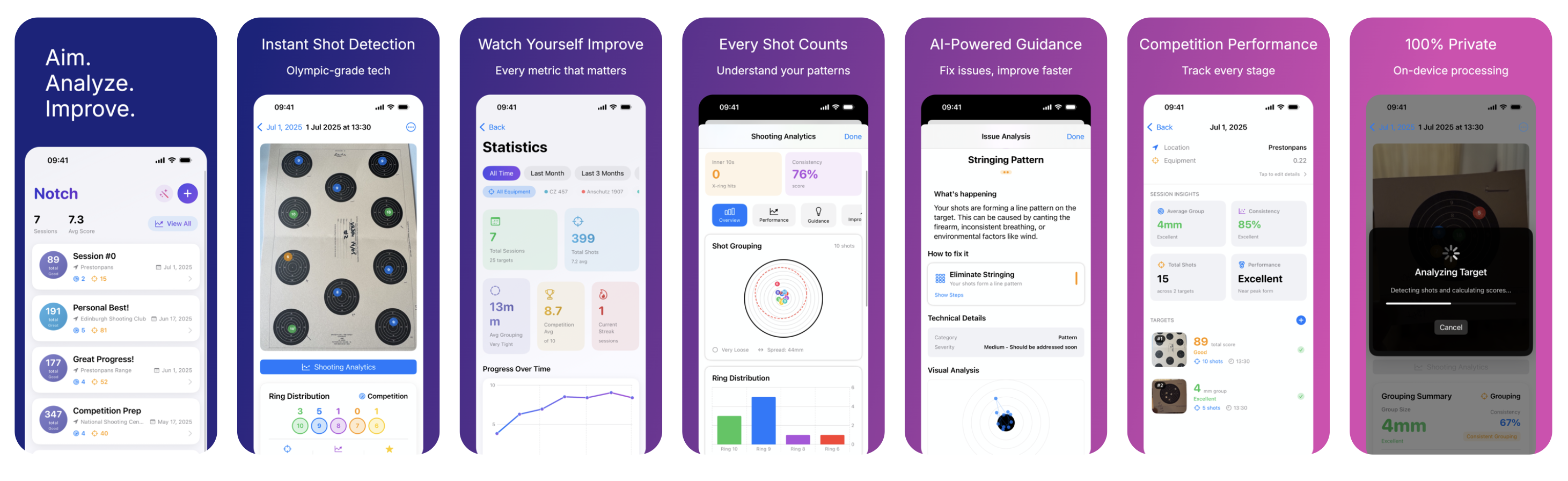
Notch
Score any match card from a photo with on-device ML
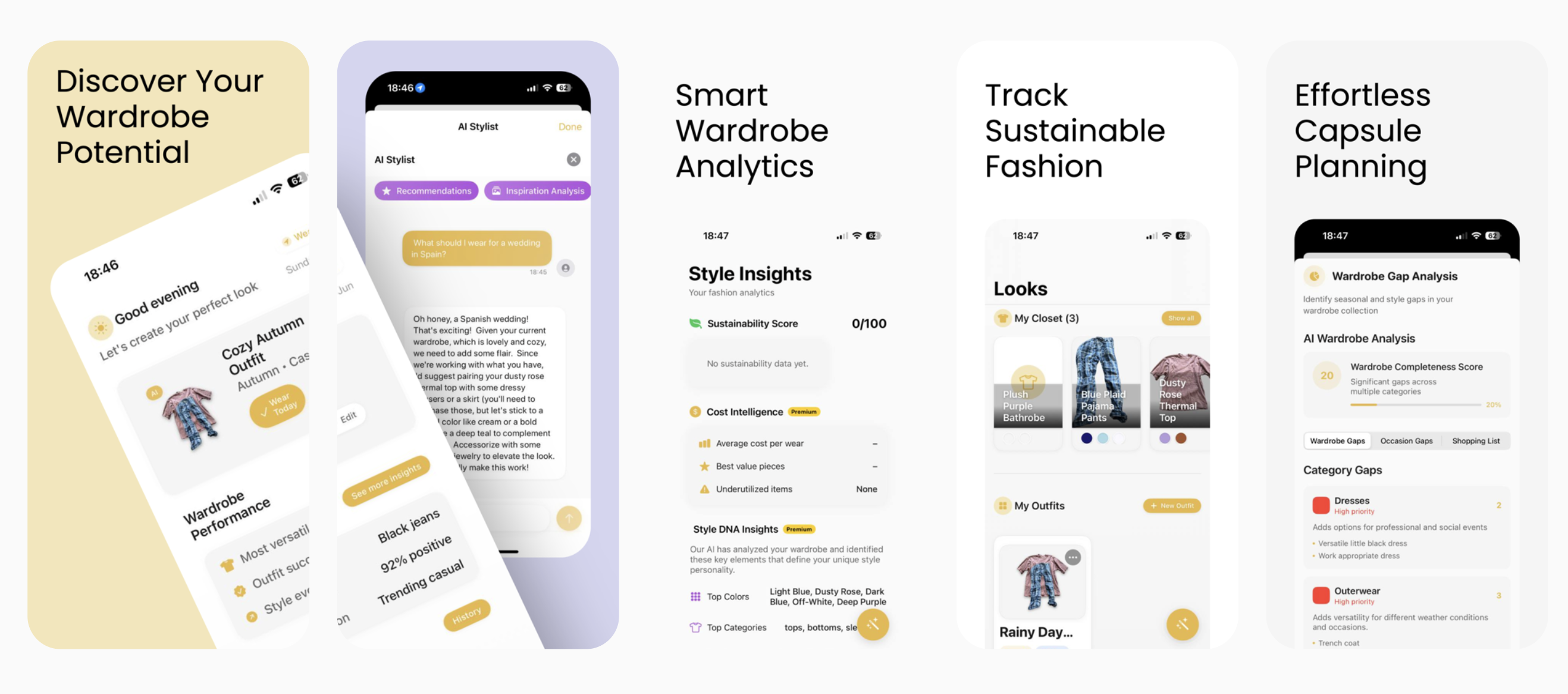
Layered
Turn your selfies into a personal AI stylist

murmur
Practice difficult phone calls with AI. Build confidence, reduce anxiety.

Folks tend to use Python or R for natural language process. Well, iOS developers probably shouldn't. Thanks to Apple, the NaturalLanguage.framework is a great tool for the majority of tasks. Let's see how we can lemmatize words, predict text and find answers all via NLP.
Common engagements
Integrate an existing model
2-4 weeks end-to-end. I write the glue code, run device-class testing from iPhone 12 through the current generation, design the update strategy (bundled vs fetched), and plan the fallback for when inference fails. The fallback matters more than the happy path.
Ship a PyTorch/TF model to Core ML
I convert the model via coremltools, debug the inevitable 'it converts but behaves differently' step, and add version-gate hygiene so the next iOS doesn't silently break inference.
Architect a new ML-backed feature
Product brief in, architecture out. I tell you whether on-device is the right call and what the fallback looks like.
Questions
I need an iOS consultant for on-device ML - is that you?
Yes. On-device Vision, Core ML, Natural Language, and voice are the whole value of three of my own apps - Notch, Layered, and murmur - so this is week-to-week work for me. Typical engagements are integrating a model you already have, converting a PyTorch or TensorFlow model to Core ML, or deciding whether on-device is the right call at all.
How do I decide between on-device and server-side?
On-device wins when any of these apply: the feature must work offline, latency needs to be under ~100ms, per-inference cost matters, or you can't send the data off-device. If none apply, server-side is usually cheaper and more maintainable.
Will the model fit in our app?
Almost always yes. The sharper question is whether it still fits after the next three features on the roadmap. I review your binary budget and model options before you commit.
We need to update our model after launch. How does that work?
It comes down to whether the model ships in the binary or gets fetched at runtime, and that trade-off, release cadence against complexity, is a product call as much as a technical one. The teams that get into trouble are the ones that half-do both and inherit the bugs of each. I make that call with you before it is baked into the architecture.
We have a model that works in Python. Can you ship it in our iOS app?
Yes. The conversion from PyTorch or TensorFlow to Core ML is the part most teams underestimate: outputs drift from the source model, some layers don't convert cleanly, model size and inference speed surface as ship blockers. I handle the conversion, device-class testing across iPhone generations, and the fallback path for when on-device inference fails. 2-4 weeks end-to-end.
Are you an agency, or do we work with you directly?
Directly - you're hiring me, one senior iOS engineer who writes the code, rather than an agency that routes you through a project manager and a team you never meet. For a lot of my clients that's the whole point: one person who owns the work end to end.
How quickly can you start?
A quick call can happen within days. For project work I usually need 1-2 weeks to clear the calendar, though I keep some buffer for urgent firefighting.
Do you work with early-stage startups?
Yes, from pre-seed to Series C and beyond. For very early teams, a short advisory engagement often makes more sense than a full build: you get the architecture guidance without committing to a large piece of work before you've validated the product.
What's included when we work together?
Everything: code, architecture decisions, code review, documentation, async Slack availability during working hours. No surprise add-ons. I bill for time spent working on your project, not for "thinking about it in the shower."
We're in a different timezone. Will that slow things down?
I'm currently in Vancouver (PST), with full overlap for North American teams. For UK and Europe, I'm online by their afternoon. For Gulf or APAC, we'd agree on overlap hours and handle the rest async. I've worked with teams from San Francisco to Dubai.
Areas I cover
Related consulting
Where I've worked CV LinkedIn
Shipping an on-device ML feature?
Tell me what you're working on. I reply within 48 hours.