Foundation Models & Apple Intelligence
Apple's Foundation Models framework gives your app an on-device LLM, Private Cloud Compute for the heavier prompts, image input, and custom tools the model can call. It also leaves out every device that cannot run the on-device model, which on iOS 27 is a large share of your users. I integrate the framework and build the fallback for the users it ignores, because that fallback is the part that decides whether the feature ships.
- Foundation Models integration: on-device generation, Private Cloud Compute for bigger prompts, image input, and custom tool-calling
- the device-tier fallback for the majority of iOS 27 devices that cannot run Apple's on-device model
- structured output with @Generable so the model returns typed data your app can use, instead of a string you have to parse and pray over
What clients say
"Vadim was instrumental to the success Epsy enjoyed on iOS, taking it from an idea on a Miro board to the highest rated and most downloaded app of its kind on the store."
James C. · Mobile Engineering Lead, Epsy
"We had a strict deadline, and Vadim managed to complete the job in time. He gave us meaningful feedback and suggested better approaches, not trying to blindly stick to our specification."
Founder · Pre-seed streaming service
"I can say with confidence that it will be difficult to find a better developer. Vadim is achievement-oriented, highly organized, with very good communication skills."
Alex Z. · Co-Founder, eda.so
Related work

Why your Foundation Models feature breaks in production
Apple Foundation Models run on a small on-device model with a 4096-token window, so the feature that demos fine breaks on real data and older phones.
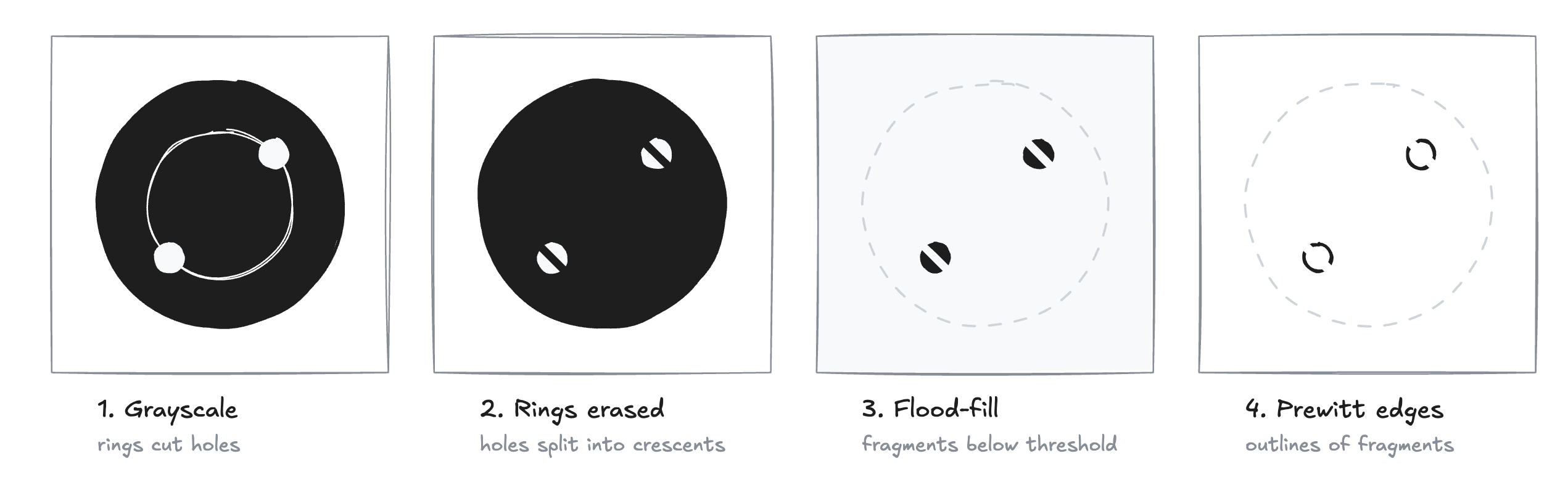
My Phone Replaced a Brass Plug
I wanted to cook venison from scratch, which meant learning to shoot, which meant keeping track of my progress, which meant porting a 2012 OpenCV paper and training a state-of-the-art computer vision model, which meant the dinner took a bit longer than expected.

murmur
Practice difficult phone calls with AI. Build confidence, reduce anxiety.

Lexie
Learn French with your adorable pet blob companion
Layered
Turn your selfies into a personal AI stylist

Folks tend to use Python or R for natural language process. Well, iOS developers probably shouldn't. Thanks to Apple, the NaturalLanguage.framework is a great tool for the majority of tasks. Let's see how we can lemmatize words, predict text and find answers all via NLP.
Common engagements
Add an Apple Intelligence feature
I take a feature from idea to shipped, running on-device where it fits and on Private Cloud Compute where it needs the capability, with typed results your code can rely on. The discipline that separates a demo from a shipping feature is handling the devices that cannot run the model at all, up front, before the crash reports arrive rather than after. That discipline is most of what you are paying for, and it is invisible in every tutorial.
Build the fallback the demo skipped
Your prototype works on the newest phone on your desk and breaks on the iPhone 12 a big slice of your users still carry. I build the tier that runs when Foundation Models is unavailable, and which form it takes (a lighter on-device path, a server call you already pay for, or an honest 'not on this device' state) is a judgment call against your product and your budget rather than a checkbox. On iOS 27 this is not an edge case; it is a large part of your install base, and skipping it ships a feature your paying users cannot see.
Move a feature off your cloud LLM bill
You are paying per token to a cloud vendor for something the on-device model can handle. I work out which prompts move on-device cleanly and which genuinely need the frontier model, migrate the ones that move, and keep a server path for the rest. I will not promise a zero bill, because the prompts that need real reasoning still belong on a server. What I give you is the migration plus the per-prompt cost difference, so the call is yours and it is an informed one.
Questions
We're adding a small language model on mobile - who consults on on-device inference?
That's my lane. I integrate Apple's Foundation Models on-device and on Private Cloud Compute, with @Generable structured output and the fallback for the devices that can't run the model - murmur, Lexie, and Layered all ship on-device AI of mine. If your value is a model you trained rather than a general LLM, that is a Core ML conversation instead.
Is Apple Intelligence free? Does this kill our OpenAI bill?
The on-device model is free to call and runs without a network. The server side, Private Cloud Compute, does not have published developer pricing yet, so nobody can tell you it zeroes your bill. What is safe to say today: prompts that fit the on-device model stop costing you per-token money on supported devices, and you get a privacy and latency win. For the prompts that need the big model, the honest move is to wait for Apple's pricing before you rip out your current vendor, and that judgment is part of what I bring.
What share of our users can actually run this?
Fewer than you would like. iOS 27 installs back to the iPhone 11, but Apple's on-device model needs much newer silicon, so a large part of your base is on a device that cannot run it. That gap is exactly why the fallback is the real work. If you only build the happy path, you have shipped a feature a chunk of your paying users will never see, and you will hear about it in the reviews.
Can the model read images now, or is it text only?
It takes images as of this year's release, which opens up features that look at a photo and reason about it: read a label, check a garment, parse a page of a cookbook. The same availability rules apply, so the image path needs its own fallback. And do not assume the image generation side is fully open to developers yet; the input side is the part you can build on with confidence today, and knowing that boundary stops you designing around a capability that may not ship to you.
We have our own model. Should we use Foundation Models instead?
Maybe for part of it. Foundation Models is a fixed Apple model: you do not control its weights, its updates, or its exact behaviour, and it will change under you with OS releases. If your value is a model you trained, keep it and run it through Core ML. If you are calling a general LLM for summaries, rewriting, or extraction, the Apple model probably covers it on-device for free. Splitting the feature along that line, rather than going all-in on either, is the decision I help you get right.
Are you an agency, or do we work with you directly?
Directly - you're hiring me, one senior iOS engineer who writes the code, rather than an agency that routes you through a project manager and a team you never meet. For a lot of my clients that's the whole point: one person who owns the work end to end.
How quickly can you start?
A quick call can happen within days. For project work I usually need 1-2 weeks to clear the calendar, though I keep some buffer for urgent firefighting.
Do you work with early-stage startups?
Yes, from pre-seed to Series C and beyond. For very early teams, a short advisory engagement often makes more sense than a full build: you get the architecture guidance without committing to a large piece of work before you've validated the product.
What's included when we work together?
Everything: code, architecture decisions, code review, documentation, async Slack availability during working hours. No surprise add-ons. I bill for time spent working on your project, not for "thinking about it in the shower."
We're in a different timezone. Will that slow things down?
I'm currently in Vancouver (PST), with full overlap for North American teams. For UK and Europe, I'm online by their afternoon. For Gulf or APAC, we'd agree on overlap hours and handle the rest async. I've worked with teams from San Francisco to Dubai.
Areas I cover
Related consulting
Where I've worked CV LinkedIn
Integrating Foundation Models?
Tell me what you're working on. I reply within 48 hours.